TT® Score: 機械学習を活用したトレードの監視
トレード監視の必要性
金融業界は、2008 年の世界的な金融危機の発生を機に、尋常ではない大きな問題を経験してきました。特に昨年は、米国を始め各国で、銀行や金融取引業界のすべての局面にわたって、前例のない規制の改革が実施されました。
規制者とコンプライアンス スタッフの両方が直面する最大の問題の1つに、監督する取引所の参加者が、現在の取引所の規制に完全に準拠していることを一貫して保証するということです。規制者は、マーケットが公平で効率的であること、そしてコンプライアンス スタッフが、破壊的かつ意図的な取引操作により非常に大きな損益をこうむりかねないことを確実に理解していることを確証しようとしています。
結果として、禁止された市場の慣行を迅速かつ正確に検知することが、金融業界のすべての業務にとって最重要課題となったのです。
従来のパラメータに基づいた監視ツール
従来の監視ツールは、第三者ベンダーからのものや社内で開発されるものが多く、そのほとんどはパラメータ ベースか、ルール ベースのものです。それらは、任意の時間のウィンドウ上に if-then ロジックの設定可能なしきい値で重ね合わされた If-Then ロジックを適用させることで機能します。理論上、これらのパラメーターを設定できる機能により、ユーザーは業務上の需要に対し通知の出力をカスタマイズできますが、実際には、このような設定は、結果の妥当性ではなく、部署内の通知の確認を目的として設定されますこれは、コンプライアンス スタッフにとって深刻なリスクとなります。というのは各しきい値の背景にある理論が、規制の調査に耐えることができ、会社の業務モデルや顧客基盤に照らして防御的である必要があります。パラメータがきつすぎると、乱用行為を見逃してしまう危険があり、パラメータが緩すぎると、記録は偽陽性で充満することになります。
このパラメータ設定をさらに複雑にすることで、小規模なプロップ会社から取引所まで、監視を必要とするすべての団体が、いつでも様々な取引ストラテジーを使用できます。ストラテジーの中には、一度に 1,000 銘柄を取引するものもあれば、別のストラテジーは、1銘柄以上の発注はまったくない場合があります。口座が取引高や取引スタイルのどの範囲にあっても、すべてに対して潜在的な乱用行為を監視する必要があります。これは、パラメータ基盤の監視ツールが陥るところです。監視ツールが、合計出来高や注文サイズ、取消率などの柔軟性に欠ける要因で構成されている場合、その効果は特定の流動性プロファイルの、特定の銘柄の操作に限られてしまうので、特定のプロファイル外で銘柄にて偽陰性が生じることになります。
従来の監視ツールの柔軟性に欠けるしきい値は、同様に他の方法でも偽陰性を引き起こします。例えば、完全なスプーフィング スキームは少ないといえます。多くのスキームはトレーダーが制御できる範囲外の、雑音、意図しない約定、便宜主義的な約定、遅い取消、さまざまな注文枚数や一般的な不確定性が含まれています。例外なく、訓練を受けていない人間にでも明らかに分かるスプーフィング操作とは、任意のしきい値の条件を満たしていない操作の局面のため、フラグされません。例えばスプ―フ注文は部分的に取り消されたものか、または1つの側が有益なバルク執行を受信した場合でもマーケットの両側で約定が発生した場合などです。事前設定のスプーフィングしきい値からのどのような小さな偏差でも、パラメータ ベースの通知を生成するのに必要な、正確な事象の連続チェーンが乱されます。
取引監視に対する機械学習の試み
機械学習とは、厳しい「if-then」ロジックや決定ツリーに必ずしも従わないアルゴリズムの訓練に関わる、人口知能 (AI) の分野を示しています。どちらかというと、機械学習アルゴリズムは「機能」を有効に使用します。これらの機能を使って、アルゴリズムは自動的に、動作の操作のクラスタを集約し、既知の規制ケースからの取引パターンの類似性に基づいてスコアを出します。図A を参照してください。
機能は、犯罪例だけでなく、すべての発注や取引がきちんと監視されるように適用されます。さらに、規制者やコンプライアンス スタッフが、初回インストールの際にパラメータしきい値を設定する必要もなく、またこれらのしきい値の今後のメンテナンスの必要もありません。
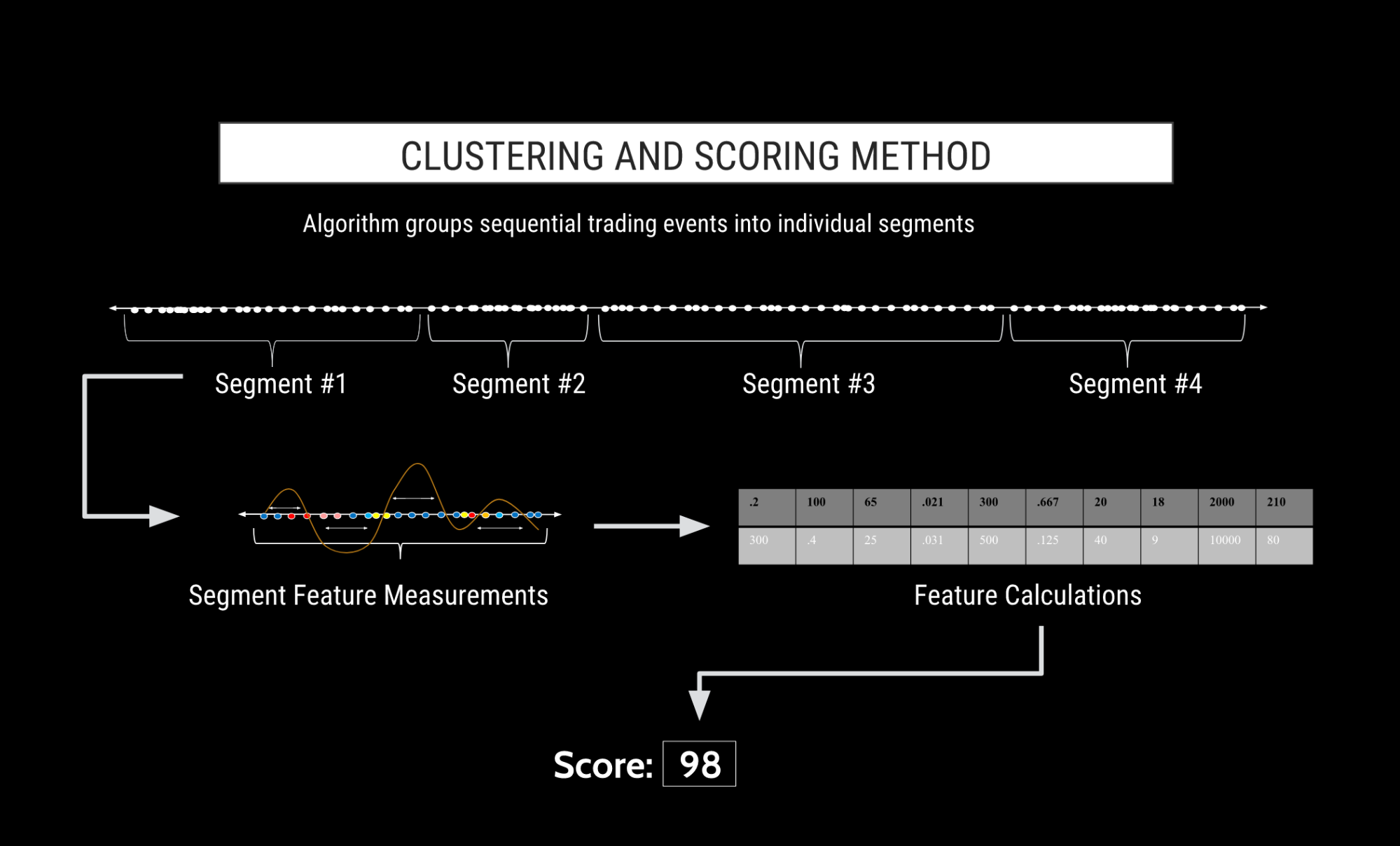
図 A
機械学習の学習データの適用
弊社は、機械学習の検知システムの神経皮質 (モデル) を訓練する際に使用する数々の情報源からトレーニング データを収集しました (多くは正規の規制例から収集)。トレーニング データでは、各モデルが類似した破壊的または意図的な取引動作を識別する際に利用できる、入力パターンを提供しています。
規制データが特定のタイプの破壊的かつ意図的な取引操作で利用できない場合、弊社は金融業界のビジネス側と規制側の両方の経験をもつドメインの熟練者が開発したカスタム トレーニング データを利用して、モデルの訓練を行います。
アルゴリズムのクラスタリング
TT Score の高度なクラスタ アルゴリズムは、時間やトレーダー、金融銘柄やその他の注文操作の近接度などの要因に基づいて、トレーダーの操作を「クラスタ」に分離します。各クラスタはトレーダーのシステム履歴の時間のスライスであり、アルゴリズムはそこで、クラスタに含まれている操作はトレーダーによる特定の操作や一連の操作に関係している可能性が高いと決定します。クラスタの長さは、数分から1秒以下まで様々です。トレーダーがとるすべての操作はクラスタに含まれていて、1つのクラスタに含むことができるワークフロー イベント数に上限はありません。
機械学習を機能させるには、トレーダー間の操作と、以前に規制的な注意を生じさせていた操作とを図るための、有効なデータ ポイント セットが必要となります。クラスタはこの測定可能な情報が豊富です。というのは、クラスタの長さにおいてはトレーダーによる連続した各注文操作が含まれています。
各クラスタは、一連の注文操作を含んでいるので (発注、注文の変更や取消など)、「目的のパケット」と考えられる可能性があります。これらはトレーダーのワークフロー イベントの近接度に関連していると考えられます。またクラスタには、レガシー通知を発生させる特定の注文イベントではなく、すべてのクラスタ期間のイベントが含まれているので、潜在的な乱用好意の完全な内容が取得・分析・視覚化されて、さらに詳しく調査できます。
Fさらにクラスタ的方法は、任意の時間枠に依存していないので、ワークフロー イベントの頻度に関わらずクラスタ方法は効果的といえます。クラスタ アルゴリズムでは、徐々に取引間の時間間隔に基づいてクラスタを終了する必要のある時間の区分が動的に変化します。これにより、ミリ秒間隔や手動取引を生ずる両方の高頻度取引 (HFT) に対して効果的なクラスタを実現できます。
スコア モデル機能
トレーニング データや注文取引データ、クラスタはすべてモデルをフィードします。各モデルは、乱用的な取引行為や意図的な取引行為の特定のカテゴリに焦点を合わせます。例えば、スプーフィング類似性モデルは、単純なスプーフィング行為の他、レイヤリング、レイヤーの破壊、フリッピングやバキューミング行為を含んでいます。他のモデルは乱用メッセージやモメンタム イグニッション、ピニング、ウォッシュ トレード等に焦点を合わせます。
類似性スコア
規制者やコンプライアンス スタッフが直面する最も大きな課題の1つとして、焦点を当てるポイントを決定して、効果的な監視の命令を確実に実行することです。従来のパラメータ ベースの監視ツールは、膨大な量の重要でない通知を生成します。つまり膨大な量の中のほぼわずかなデータのみが重要と考えられます。分析は、幾つかの関連結果が最終的に検出されるまで、各通知に同等の時間を費やし、100~1000個のアラートから行う必要があります。
「類似性スコア」の観念とは、過去の規制操作との数学的な類似性の程度に基づいて、各アラートをスコア化することで、この問題に対処することです。このリスクベースの方法を利用すると、規制者やコンプライアンス スタッフが時間と人件費を最も必要な場面に割り当てることができます。
類似性スコアは 0 ~ 100 の値で各クラスタに生成されます。100 のスコアは、過去に規制的な注意が必要であったパターンと非常に高い類似性を示していて、0 は非常に低い類似性を示しています。この方法で TT Score は、どのクラスタが今後に規制の注意が必要となる高いリスクを持っているか、そしてレビューの必要性の最も高いクラスタについて、特定のガイドラインをユーザーに提供しています。
視覚的データの効果の重要性
TT Score は、固有のユーザー インターフェースを通じた処理済み取引データの優先度設定と分析を行い、特に規制的コンプライアンスを使って大量データを処理するように設計されています。データの何処にリスクが存在するのか、またどのようにリスクが配信されているか、またどのようにリスクが徐々に変化していくかを、ユーザーが理解できるように支援するための、固有のビジュアル ツールを幾つか提供しています。これにより、規制者やコンプライアンス スタッフは「曲がり角からでも見える」能力を使って、問題になる前に破壊的かつ意図的な取引操作を回避できるように、事前対策を講じることができます。
Heatmap や Scorecard、Market Ladder Replay などのツールには、各クラスタの重要な統計の瞬間的な要約が表示されます。そしてその操作が発生した当時の市況の背景で各クラスタを分析できる機能をユーザーに提供しています。これらのリサーチ ツールは、規制者やコンプライアンススタッフが、トレーダーの意図を数値化し、トレーダーの操作がマーケットに与えた影響を理解できるように、うまく統合されています。この方法は、定期的に何個のアラートが消去されるかを単純に見るのとはまったく逆に、どのように組織内でリスクが軽減されるかを、ユーザーは単刀直入かつ視覚的な表示を得ることができます。
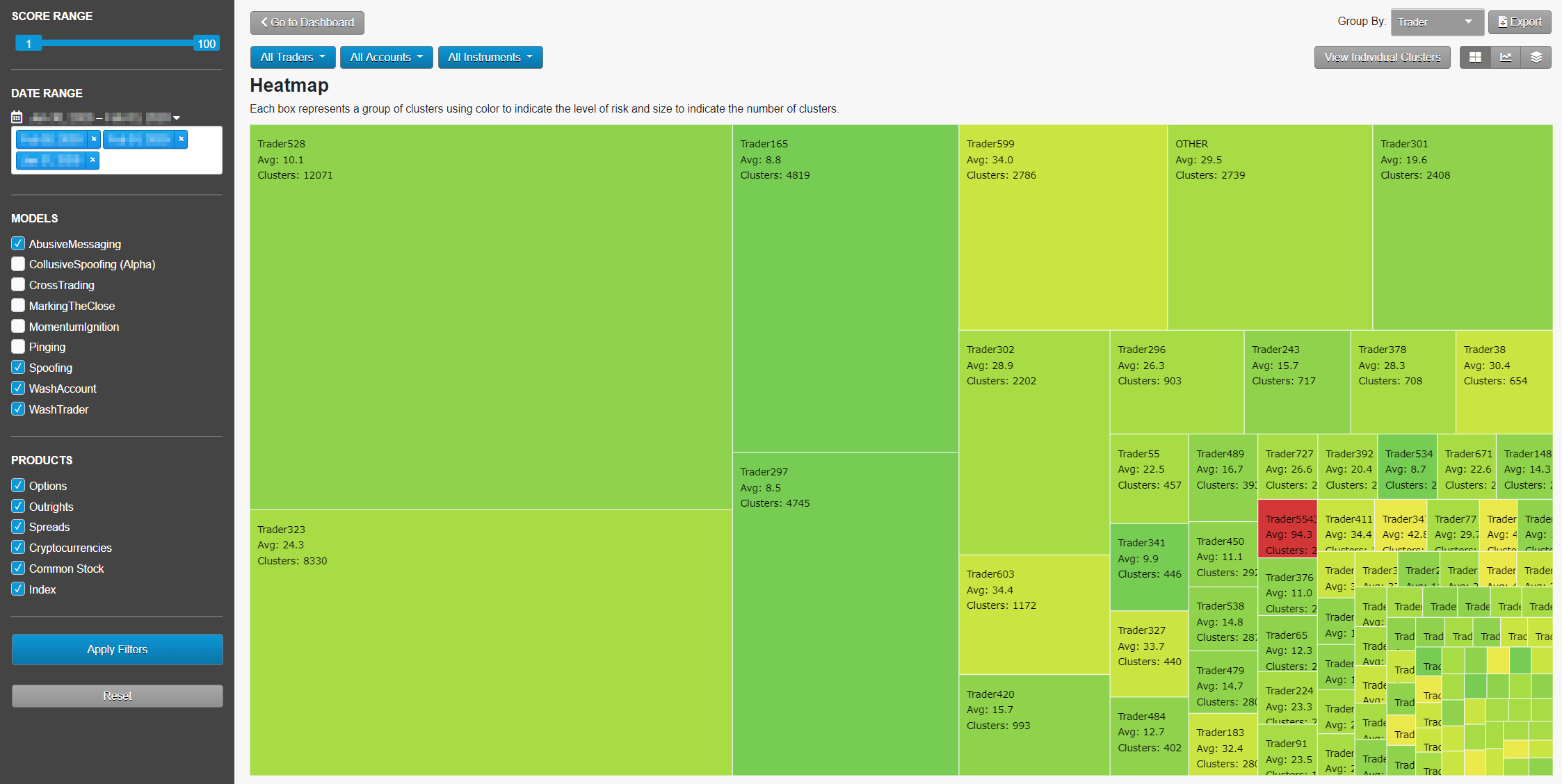
リスクの焦点: Heatmap
Heatmap では、規制措置の事例に非常に類似している取引操作を生成しているのが、どのトレーダーや口座であるかを確認できます。鮮明な赤色は、リスクの高いクラスタを示していて、それぞれの四角のサイズはクラスタ数を示しています。以下の画面で、Trader88 が最も多いクラスタを生成しているだけではなく、最も高い平均の類似スコアを生成しているのが分かります。Heatmap を使って、最も高いリスクを生成する取引操作を確認するのに必要な時間と人件費を、一目で効果的に割り当ることができます。
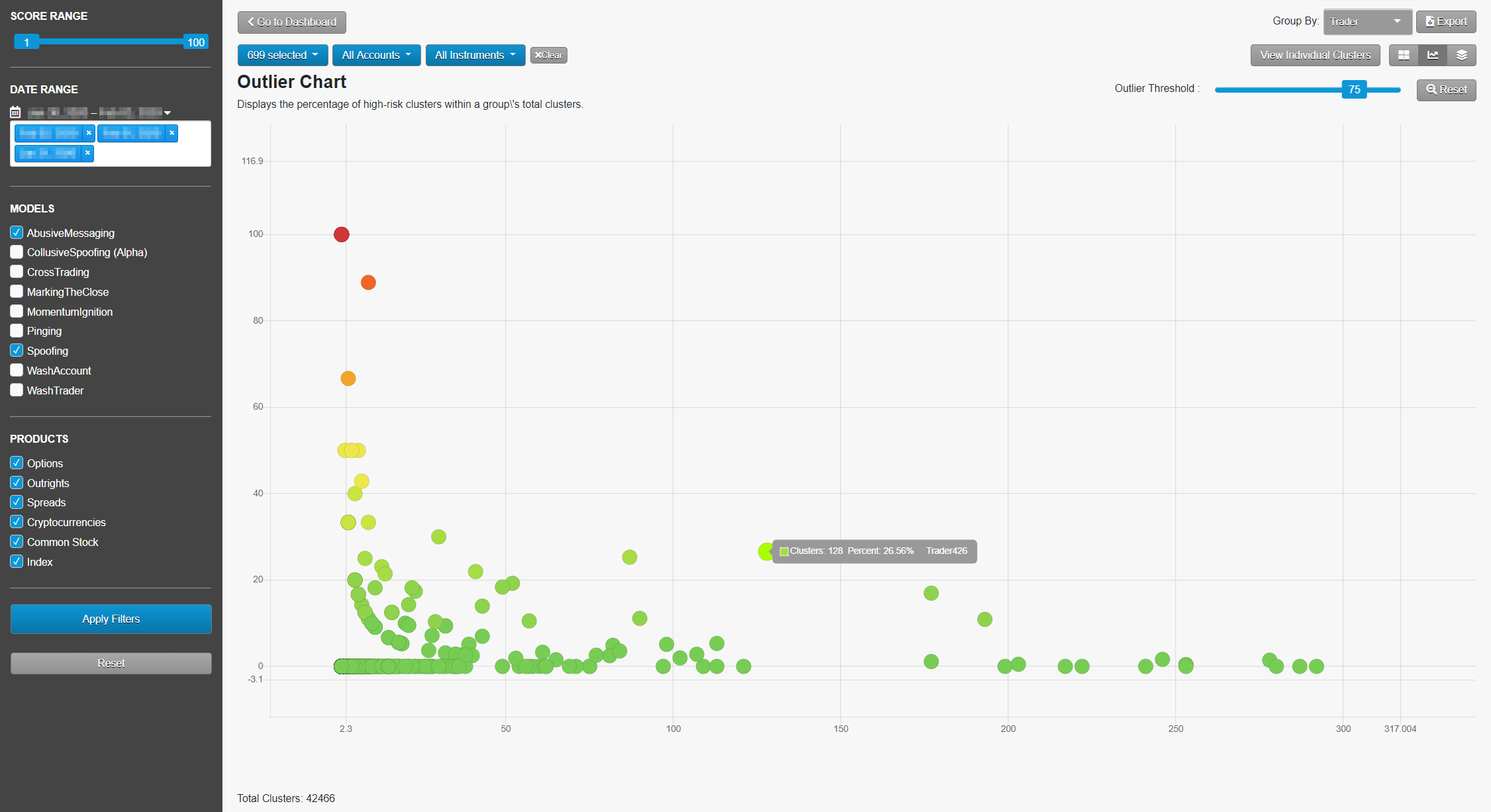
ビッグデータの視覚化: Outlier チャート
Outlier チャートには、1画面での合計クラスターの表示に比較した、各会社のハイリスク クラスタのパーセント数が表示されます。これで、様々な顧客やトレーダー クラスタの容量をふくむビッグ データのセットで問題のある取引を簡単に探知できます。ユーザーは、1つの視覚表示で複数月にわたる数千個のエントリを確認できます。つまり10個のクラスタを生成する小規模のトレーダーは、数千個のクラスタを生成する口座の中で見失われることはありません。さらに、ユーザーは「高リスク」を構成する定義を各自で設定できます。既定の高リスクスコアは 80 となっています。
取引操作の調査: Scorecard
Scorecard では、クラスタの重要な統計の要約が表示される他、取引行為により形成されたパターンの初期の視覚化が表示されます。コンプライアンス担当者は、注文のトランザクションの特定のクラスタで何が起こったかをすばやく確認できます。Scorecard の下部にあるチャートでは、クラスタ内で取引されるの限月の枚数が表示されます。また関連する一定の期間にわたって、注文や取引操作がどのように展開されるかを表示されます。
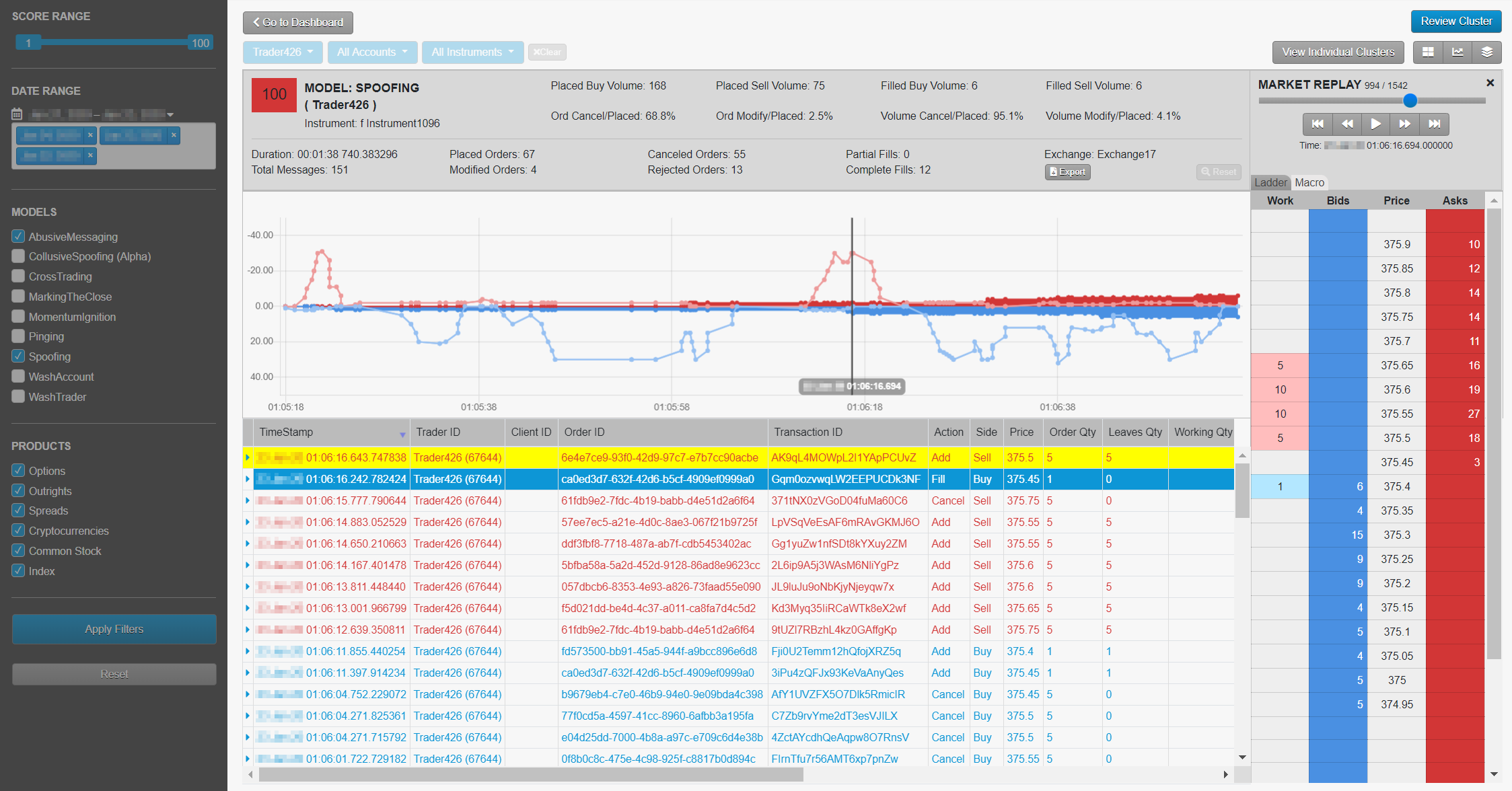
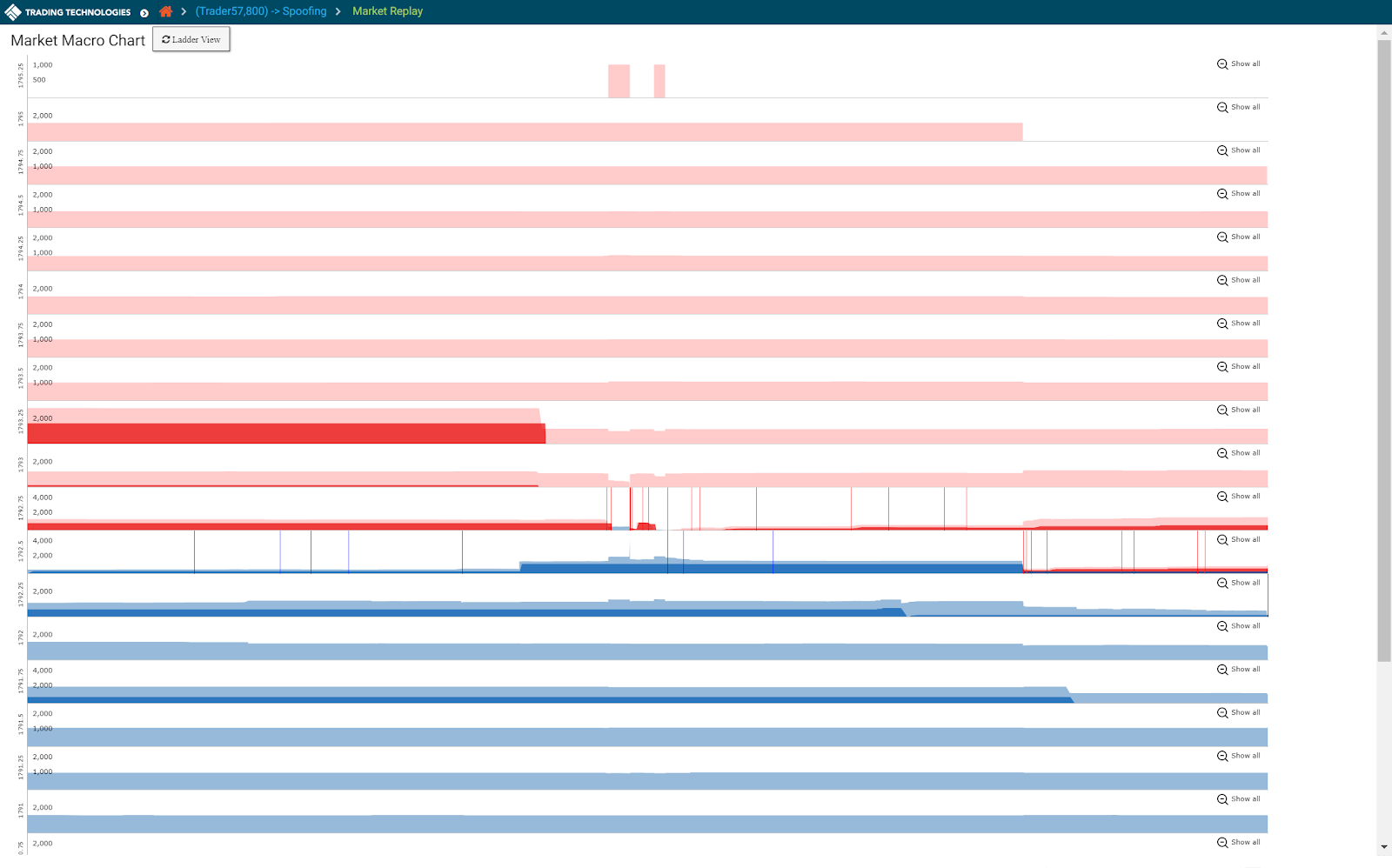
マーケット データの再生: Market Ladder Replay と Macro チャート
Market Ladder Replay は、ラダー形式のインターフェースでレベル 2 マーケット データに重ねて、取引行為をコマ送り再生できるツールです。はしごの深さは 10 ティックであり、注文一覧の各関連の参加者に対する注文も含め、すべてのマーケット データが表示されます。ユーザーは特定のクラスタ内で操作の停止や開始、再生を行い、トレーダーの注文がどのように市場に影響を与えるかを確認したり、注文一覧で発生した一連のイベントを正確に理解できます。また操作の速度を遅めて、ミリ秒間隔で発生した高頻度取引ストラテジーによって発注された注文を視覚化することができます。
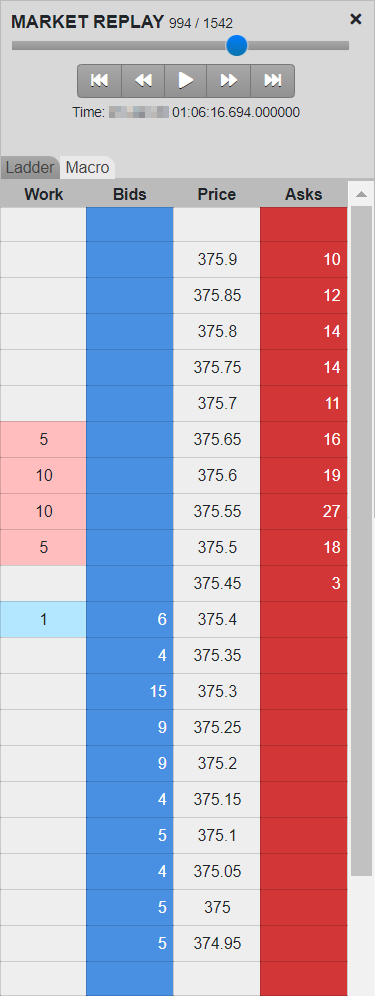
Macro チャートでは、Market Ladder Replay と同様の詳細を提供していますが、1画面にクラスタの全期間におけるトレーダーのデータとレベル 2 マーケット データの両方が表示されます。この1画面のビューでは、残りのマーケットと比較した場合の、一定期間にわたるトレーダーの執行パターンや、様々な価格帯での約定待ち枚数が強調表示されます。 これにより、トレーダーの操作のパターンや該当するマーケットの反応を素早く評価することができます。